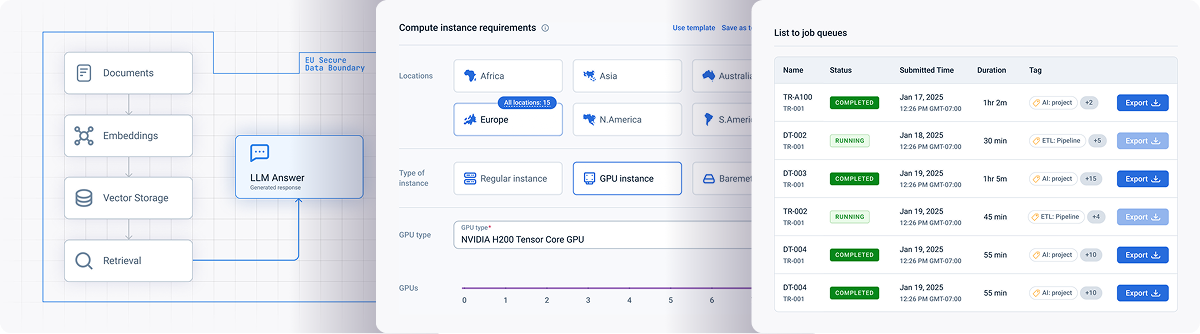

Configure your pilot
Hours shown = how long your $500 credit runs each config
↓ START HERE
Starter Inference
NVIDIA L4 24 GB · 4 CPU · 16 GB RAM
714 hr
$0.70/hr
★ MOST POPULAR
Production Inference
NVIDIA L40S 48 GB · 4 CPU · 32 GB RAM
269 hr
$1.86/hr
Fine-tuning Lab
NVIDIA A100 80 GB · 24 CPU · 220 GB RAM
136 hr
$3.67/hr
Advanced Training
NVIDIA H100 80 GB · 16 CPU · 256 GB RAM
73 hr
$6.88/hr
↔ MAX COMPUTE
Frontier Models
NVIDIA H100 94 GB · 40 CPU · 320 GB RAM
72 hr
$6.98/hr
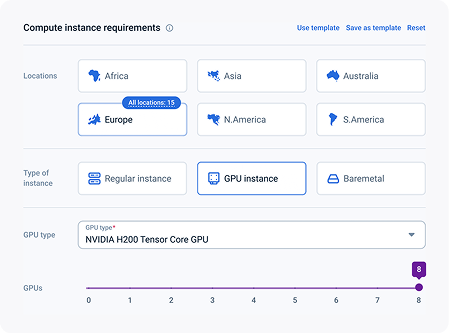
See exactly what you get
$500
Your Pilot Budget
714 hr
NVIDIA L4 24 GB · 4 CPU · 16 GB RAM
- Dedicated engineer: setup + tuning
- Migration support: 1 workload